Cross-shard queries
If a client can't or doesn't specify a sharding key in the query, PgDog will send that query to all shards in parallel, and combine the results automatically. To the client, this looks like the query was executed by a single database.
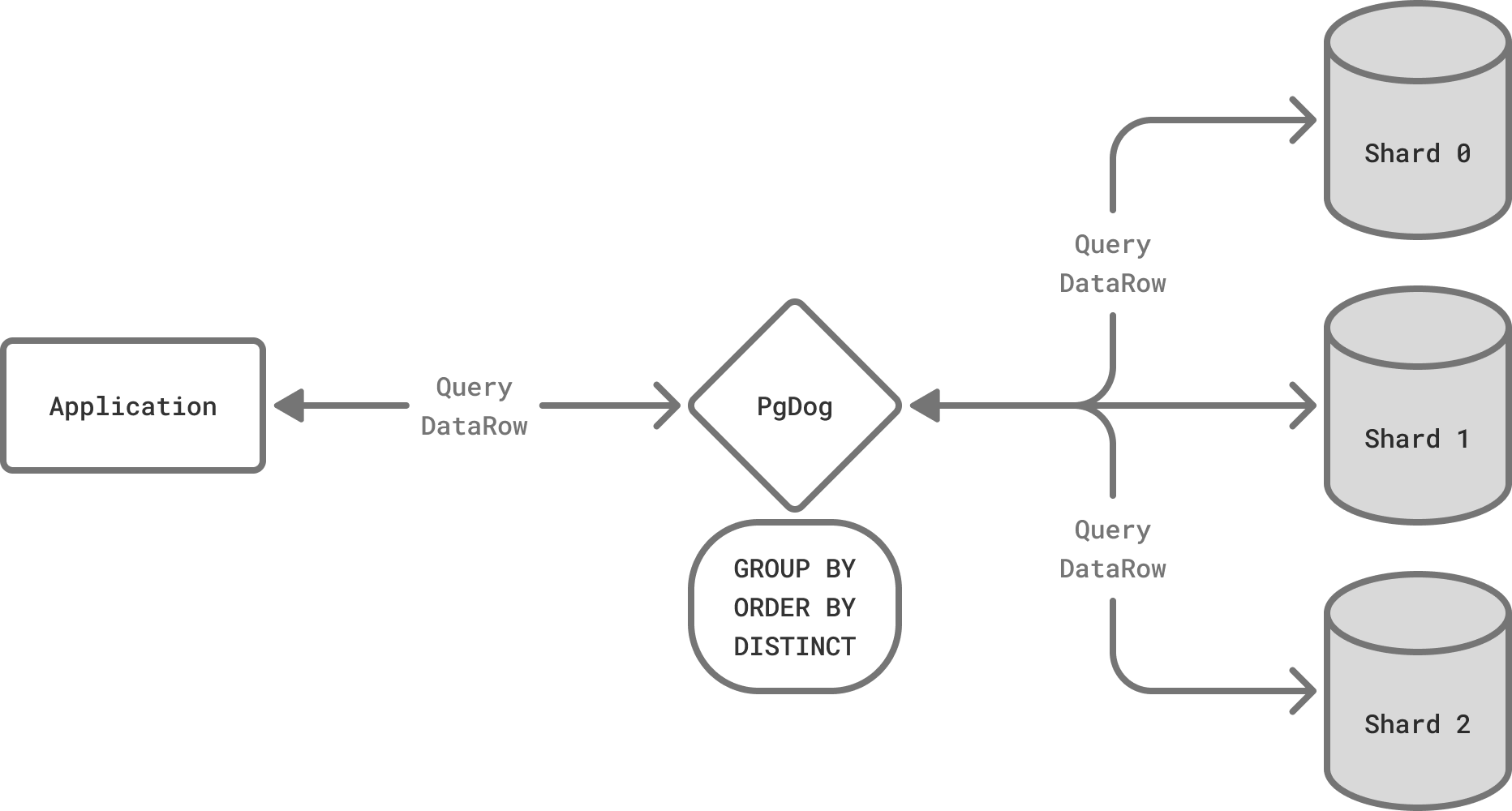
How it works
PgDog understands the Postgres protocol and query language. It can connect to multiple database servers, send the query to all of them, and collect DataRow messages, as they are returned by each connection.
Once all servers finish executing the request, PgDog processes the result, performs any requested sorting, aggregation or row disambiguation, and sends the complete result back to the client, as if all rows came from one database server.
Just like with direct-to-shard queries, each SQL command is handled differently, as documented below.
SELECT
Cross-shard read queries are executed by all shards concurrently, which makes PgDog an efficient scatter/gather engine, with data nodes powered by PostgreSQL.
The SQL language allows for powerful data filtration and manipulation. While we aim to support most operations, currently, support for most cross-shard operations is limited, as documented below.
| Operation | Supported | Limitations |
|---|---|---|
Simple SELECT |
None. | |
ORDER BY |
Target columns must be part of the tuples returned by the query. | |
DISTINCT / DISTINCT BY |
〃 | |
GROUP BY |
Limited to cumulative functions only and columns returned by the query. HAVING clause not handled yet. |
|
| CTEs | CTE must refer to data located on the same shard. | |
| Window functions | Not currently supported. | |
| Subqueries | Subqueries must refer to data located on the same shard. They cannot be used to return the value of a sharding key. |
Sorting with ORDER BY
If the query contains an ORDER BY clause, PgDog can sort the rows once it receives all data messages from all servers. For cross-shard queries, this allows us to retrieve rows in the specified order.
Two forms of syntax for the ORDER BY clause are supported:
| Syntax | Notes |
|---|---|
ORDER BY column_name |
The column must be present in the result set and named accordingly. |
ORDER BY <column position> |
The column is referred to by its position in the result, for example: ORDER BY 1 DESC. |
Sorting by multiple columns is supported, including opposing sorting directions, e.g.: ORDER BY 1 ASC, created_at DESC.
Example
Since the id column is part of the result, PgDog can buffer and sort rows after it receives them from all shards. While referring to columns by name works well, it's sometimes easier to use column positions, for example:
The latter pattern ensures that the only rows used for sorting are the ones included in the result returned by Postgres.
Aggregates with GROUP BY
Aggregates are transformative functions: instead of returning rows as-is, they return calculated summaries, like a sum or a count. Many aggregates are cumulative: the aggregate can be calculated from partial results returned by each shard.
Support for all aggregate functions is a work in progress, as documented below:
| Aggregate function | Supported | Notes |
|---|---|---|
COUNT / COUNT(*) |
Supported for most data types. | |
MAX / MIN |
〃 | |
SUM |
〃 | |
AVG |
Requires the query to be rewritten to return both AVG and COUNT. |
|
percentile_disc / percentile_cont |
Very expensive to calculate on large results. | |
*_agg |
Not currently supported. | |
json_* |
〃 | |
Statistics, like stddev, variance, etc. |
〃 |
Example
Aggregate functions can be combined with cross-shard sorting, for example:
HAVING clause
The HAVING clause is not currently supported.
INSERT
If the INSERT statement specifies the sharding key, it's routed directly to one of the shards. Otherwise, it becomes a cross-shard statement.
Cross-shard INSERT statements are handled in two distinct ways, depending on what they do. For INSERT statements into unsharded (also called omnisharded) tables, the statement is sent to all shards concurrently. This ensures the data is identical on all shards, as desired.
If the INSERT is creating a row in a sharded table, but the primary key is database-generated and used for sharding that table, the statement is sent to only one of the shards, using the round robin algorithm.
For example:
Instead of creating one user per shard, which would cause duplicate entries, PgDog will let the database generate a globally unique primary key and place it on one of the shards only. This ensures even data distribution across the entire database cluster.
CREATE, ALTER, DROP
CREATE, ALTER and DROP, also known as Data Definition Language (DDL), are by design, cross-shard statements. When a client sends over a DDL command, PgDog will send it to all shards in parallel, ensuring the table, index, view and sequence definitions are identical across the database cluster.
Atomicity
DDL statements should be atomic across all shards. This is to protect against a single shard failure to create a table or index, which could result in an inconsistent schema. PgDog can use two-phase commit to ensure this is the case, however that means that all DDL statements must be executed inside a transaction, for example:
BEGIN;
CREATE TABLE users (
id BIGSERIAL PRIMARY KEY,
email VARCHAR NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
COMMIT;
Idempotency
Some statements, like CREATE INDEX CONCURRENTLY, cannot run inside transactions. To make sure these are safely executed, you have two options: use manual routing and execute it on each shard individually, or write idempotent schema migrations, for example:
DROP INDEX IF EXISTS user_id_idx;
CREATE INDEX CONCURRENTLY user_id_idx ON users USING btree(user_id);
Under the hood
PgDog implements the PostgreSQL wire protocol, which is well documented and stable. The messages sent by Postgres clients and servers contain all the necessary information about data types, column names and executed statements, which PgDog can use to present multi-database results as a single stream of data.
The following protocol messages are especially relevant:
| Message | Description |
|---|---|
DataRow |
Each DataRow message contains one tuple, for each row returned by the query. |
RowDescription |
This message has the column names and data types returned by the query. |
CommandComplete |
Indicates that the query has finished returning results. PgDog uses it to start sorting and aggregation. |
The protocol has two formats for encoding tuples: text and binary. Text format is equivalent to calling the to_string() method on native types, while binary encoding sends them in network-byte order. For example:
Since PgDog needs to process rows before sending them to the client, we implemented parsing both formats for most data types, as documented below.
Supported data types
| Data type | Sorting | Aggregation | Text format | Binary format |
|---|---|---|---|---|
BIGINT |
||||
INTEGER |
||||
SMALLINT |
||||
VARCHAR |
||||
TEXT |
||||
NUMERIC |
||||
REAL |
||||
DOUBLE PRECISION |
||||
INTERVAL |
No | |||
TIMESTAMP |
No | |||
TIMESTAMPTZ |
No | |||
UUID |
||||
VECTOR |
Only by L2 |
pgvector data types
VECTOR type doesn't have a fixed OID in Postgres because it comes from an extension (pgvector). We infer it from the <-> operator used in the ORDER BY clause.
Disable cross-shard queries
If you don't want PgDog to route cross-shard queries, e.g., because you're building a multitenant system with no cross-tenant dependencies, cross-shard queries can be disabled with a configuration setting:
If this setting is set, and a query doesn't have a sharding key, instead of executing the query, PgDog will return an error to the client and abort the transaction.